Almost all my books in PDF format have a fore-matter with pages numbered in lowercase roman and then the main content numbered in Arabic numerals, i.e. have a logical page numbering distinct from physical page numbering.
When referring to a specific page in the book logical page numbering is to be preferred since it’s congruent with page numbers printed in the document while physical numbering isn’t.
Unfortunately MN3 (3.1.4 on MacOS) seems to ignore and discard logical page numbering while importing PDF files and always use physical page numbers (e.g. on bottom of the window while scrolling, as prefix of exported annotations for Devonthink, etc.).
I think that using the logical page numbers would be the correct and much preferred behavior. Possible to implement that?
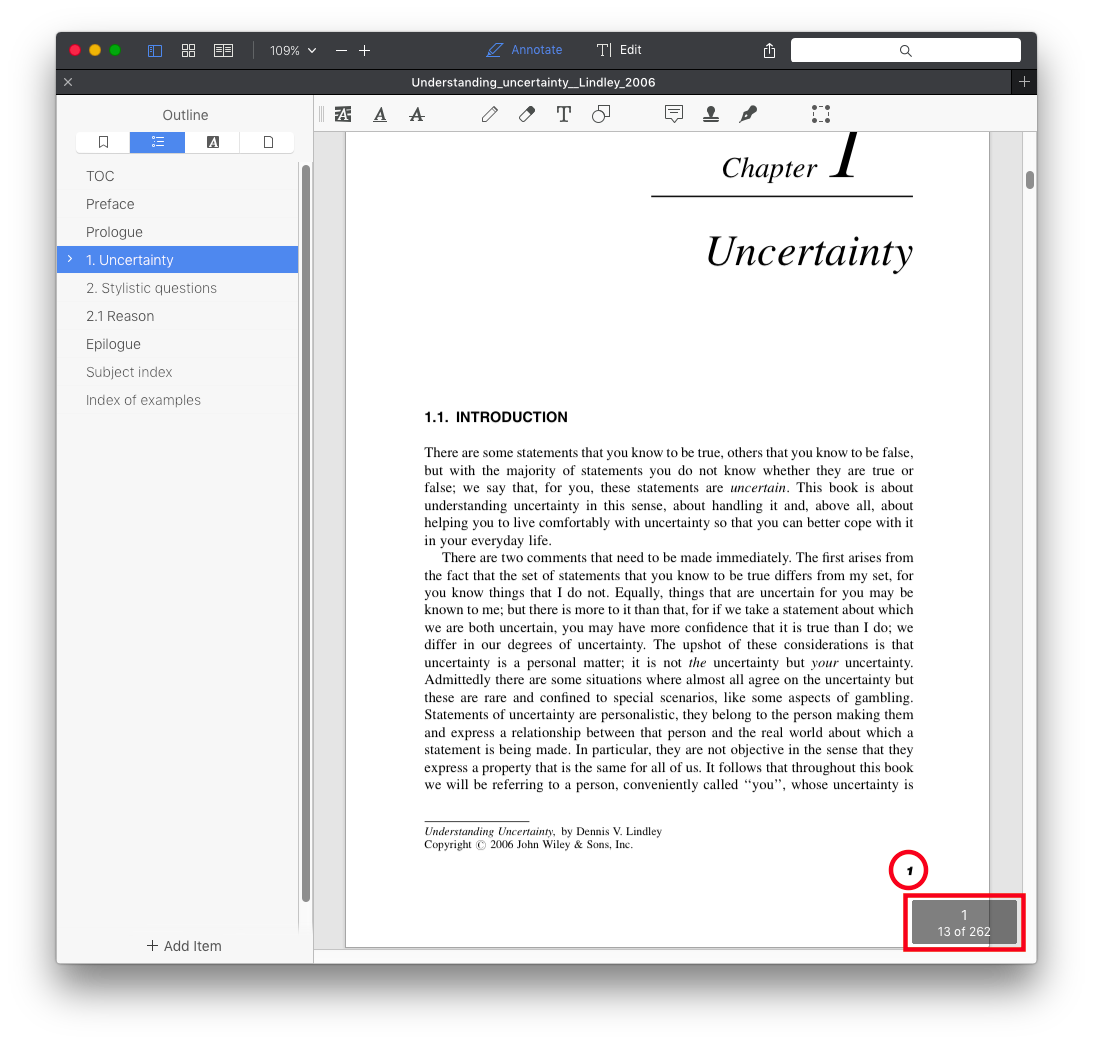
Here is an example of a book having a 12 page fore-matter then, on the 13th physical page, the logical page numbering restart from 1 to be in agrement with printed page number.
The file is viewed in PDFexpert; it shows the logical page (1) and info about physical pages (13 of 262). When I choose for instance “Go to page 2” I’ll be shown the 2nd logical page (14th physical page).
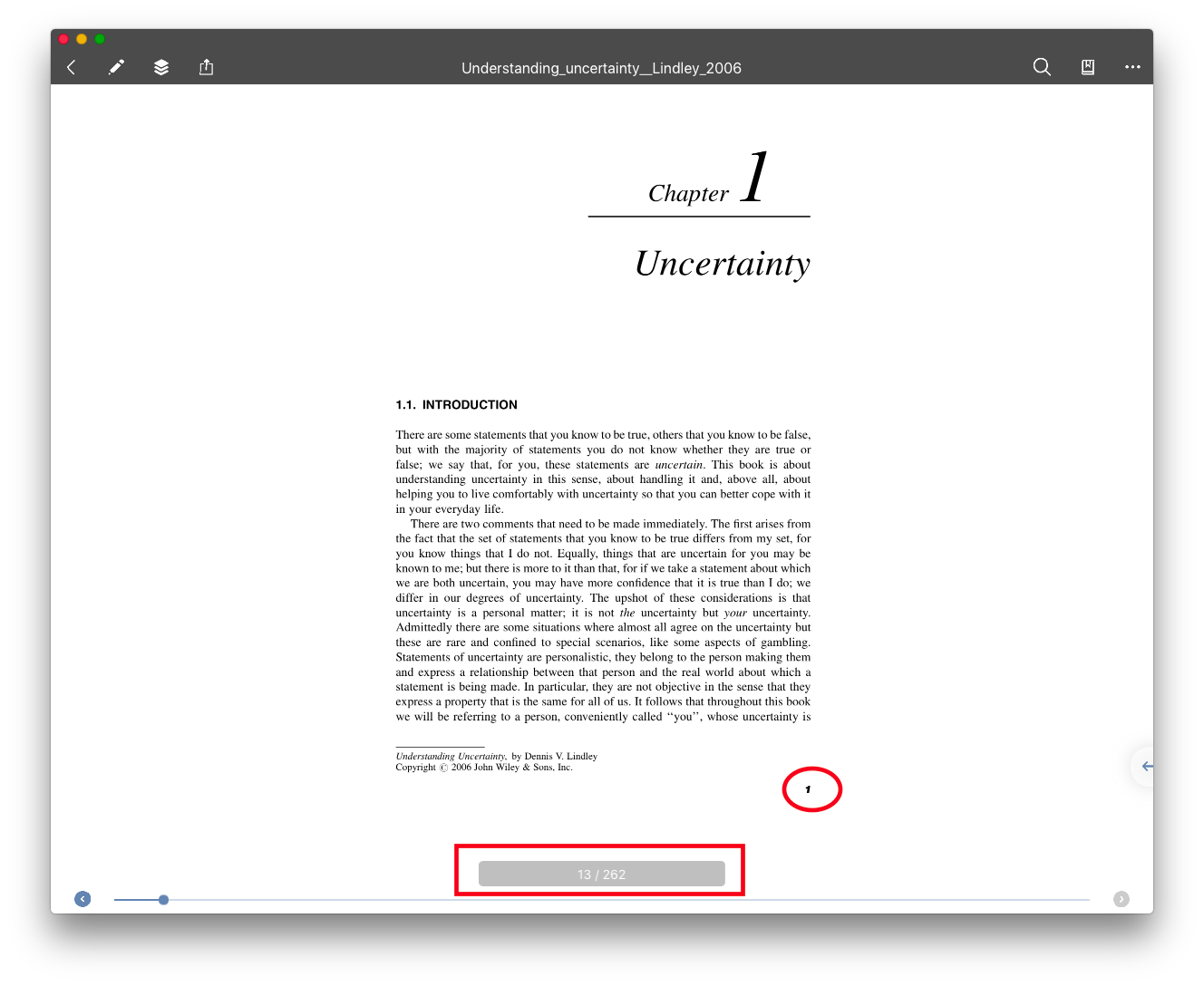
After importing the same PDF into MN3 the logical numbering has gone. MN3 shows the same page simply as the 13th one (i.e. it uses the physical page numbering).
MN3 obvioulsy refers everywhere to physical page numbering, not only in the shown overlay but also in mind-map notes, outline,etc.
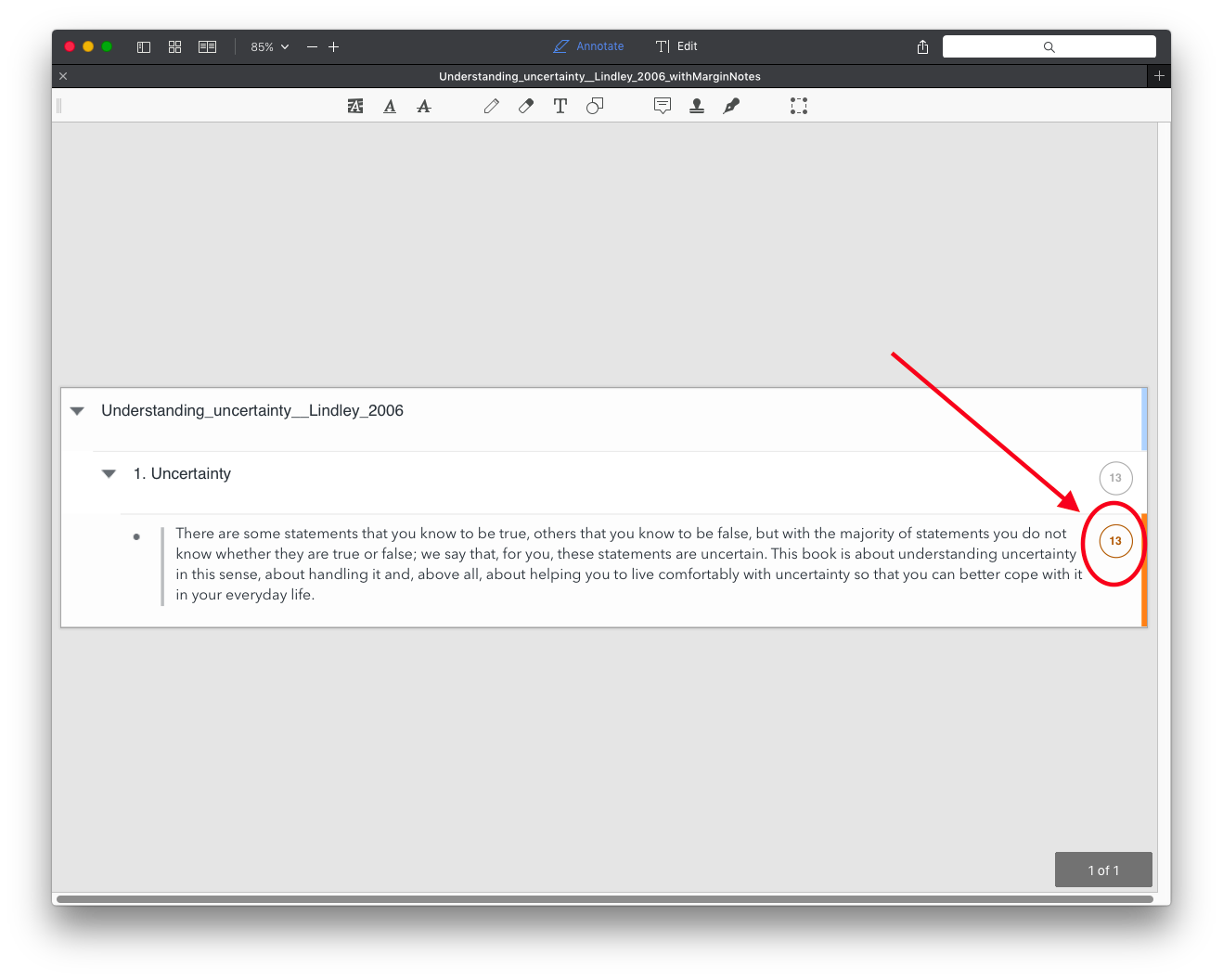
For instance, if I add a note on page 1 and then export to PDF the result is an indication to page 13.
So if I have to find the excerpt shown in the previous screeshot and don’t have MN3 installed (or must give someone else directions to find it e.g. “see page X on that book”) I’ll not find the right spot in the book because the excerpt is on page 1 of the book not on page 13 as indicated by MN3.
What I called “logical page numbering” in my original post is more precisely called “page labels” and is defined in the Document Catalog object of the PDF.
I came to make the same request. When I scan my own materials, I always make sure to change the page labels so that they match the pages printed on the document. Otherwise, using a table of contents or index is really frustrating. It’s clear that MN is reading some of the metadata about the document because it handles the table of contents outline pretty well.